
1.8 Procesamiento de Lenguaje Natural y Transformers#
Indice#
1. Fundamentos Matematicos del Lenguaje#
1.1 Definicion formal de un texto#
Un vocabulario es un conjunto finito de tokens:
Un texto (o secuencia) de longitud \(T\) es una tupla ordenada:
El espacio de todas las posibles secuencias de longitud variable es:
1.2 Modelo de lenguaje como distribucion de probabilidad#
Un modelo de lenguaje define una distribucion de probabilidad sobre secuencias:
Aplicando la regla de la cadena de la probabilidad:
El objetivo del aprendizaje es maximizar la log-verosimilitud del corpus \(\mathcal{D} = \{\mathbf{x}^{(i)}\}_{i=1}^{N}\):
1.3 Entropia y perplejidad#
La entropia de un modelo de lenguaje mide la incertidumbre promedio por token:
La perplejidad (Perplexity) es la exponencial de la entropia y la metrica estandar de evaluacion:
Interpretacion: una perplejidad de \(k\) significa que el modelo tiene la misma incertidumbre que si eligiera uniformemente entre \(k\) opciones en cada paso. Menor PPL = mejor modelo.
1.4 Divergencia KL e informacion mutua#
La divergencia Kullback-Leibler mide cuanto difiere la distribucion \(q\) del modelo de la distribucion real \(p\):
La igualdad se cumple si y solo si \(p = q\) (desigualdad de Gibbs). En NLP es util para medir cuanto el modelo de lenguaje se aleja de la distribucion real del texto.
La informacion mutua entre dos variables \(X, Y\):
Se usa, por ejemplo, para seleccion de caracteristicas y analisis de dependencias entre palabras.
2. Representaciones de Texto#
2.1 Tokenizacion#
Antes de cualquier procesamiento, el texto crudo se convierte en una secuencia de tokens. Existen tres estrategias principales:
Estrategia |
Unidad |
Vocabulario |
Ejemplo |
|---|---|---|---|
Word-level |
Palabras |
~50k–100k |
|
Character-level |
Caracteres |
~100–1000 |
|
Subword (BPE/WordPiece) |
Subpalabras |
~30k–50k |
|
Byte-Pair Encoding (BPE)#
BPE (Sennrich et al., 2016) construye el vocabulario de forma iterativa:
Inicializar \(\mathcal{V}\) con todos los caracteres.
Contar la frecuencia de todos los pares de simbolos consecutivos en el corpus.
Fusionar el par mas frecuente \((a, b) \to ab\) y agregar \(ab\) a \(\mathcal{V}\).
Repetir \(K\) veces (donde \(K\) es el tamaño de vocabulario deseado).
Propiedad clave: las palabras frecuentes quedan como tokens completos; las raras se segmentan en subpalabras conocidas, eliminando el problema de palabras fuera de vocabulario (OOV).
2.2 Representacion one-hot#
La representacion mas simple. Cada token \(w_i\) se codifica como un vector de dimension \(|\mathcal{V}|\):
Limitaciones:
Alta dimensionalidad: \(|\mathcal{V}|\) puede ser \(10^5\).
Ortogonalidad: \(\mathbf{e}_i \cdot \mathbf{e}_j = 0\) para todo \(i \neq j\). No captura similitud semantica.
Sin informacion de contexto.
2.3 Bolsa de palabras (Bag of Words)#
Un documento se representa como el vector de frecuencias de sus tokens:
TF-IDF (Term Frequency - Inverse Document Frequency) pondera la frecuencia por la rareza global del termino:
donde \(f_{w,d}\) es la frecuencia de \(w\) en el documento \(d\) y \(N\) es el numero total de documentos.
3. Modelos de Lenguaje Estadisticos#
3.1 Modelo n-grama#
El modelo n-grama aproxima el contexto con los ultimos \(n-1\) tokens:
La hipotesis de Markov de orden \(n-1\).
Estimacion por maxima verosimilitud:
donde \(C(\cdot)\) es el conteo de ocurrencias en el corpus.
Problema: si \(C(x_{t-n+1}, \ldots, x_t) = 0\), la probabilidad es cero y la perplejidad infinita. Se resuelve con suavizado de Laplace (add-\(\alpha\)):
Interpolacion (Jelinek-Mercer): combina modelos de distintos ordenes:
4. Word Embeddings#
4.1 Motivacion geometrica#
En lugar de vectores one-hot ortogonales, se buscan vectores densos \(\mathbf{v}_w \in \mathbb{R}^d\) (con \(d \ll |\mathcal{V}|\), tipicamente \(d \in \{50, 100, 200, 300\}\)) tales que la similitud del coseno refleje similitud semantica:
Hipotesis distribucional (Harris, 1954): palabras que aparecen en contextos similares tienen significados similares.
4.2 Word2Vec (Mikolov et al., 2013)#
Dos arquitecturas simétricas:
4.2.1 Skip-gram#
Dado el token central \(x_t\), predecir los tokens de contexto en la ventana \([-C, +C]\):
La probabilidad de contexto con softmax completo:
donde \(\mathbf{v}_w\) es el embedding del token central y \(\mathbf{u}_w\) el del contexto.
Complejidad: \(O(|\mathcal{V}|)\) por token — prohibitivo para vocabularios grandes.
4.2.2 Negative Sampling#
Aproxima el softmax muestreando \(K\) «palabras negativas» de la distribucion de ruido \(p_n(w) \propto f(w)^{3/4}\):
donde \(\sigma(z) = \frac{1}{1+e^{-z}}\). Complejidad reducida a \(O(K)\) por muestra, con \(K \in [5, 20]\) tipicamente.
4.2.3 CBOW (Continuous Bag of Words)#
Inverso del skip-gram: predecir el token central dado el contexto promediado:
CBOW es mas rapido; skip-gram produce mejores embeddings para palabras raras.
4.3 GloVe (Pennington et al., 2014)#
GloVe (Global Vectors) explota directamente la matriz de co-ocurrencia global.
Sea \(X_{ij}\) el numero de veces que la palabra \(j\) aparece en el contexto de \(i\). Se define:
La clave de GloVe es que la razon \(P_{ik}/P_{jk}\) encode la relacion semantica entre \(i\), \(j\) en terminos del contexto \(k\).
Esto motiva que los embeddings satisfagan:
Funcion de perdida ponderada por frecuencia de co-ocurrencia:
donde la funcion de ponderacion:
con \(x_{\max} = 100\) y \(\alpha = 0.75\) tipicamente. Reduce el peso de las co-ocurrencias muy frecuentes.
4.4 Propiedades algebraicas#
Los embeddings entrenados exhiben aritmetica vectorial:
Esto se debe a que el modelo aprende a separar dimensiones que codifican distintos ejes semanticos (genero, royalty, etc.).
4.5 FastText (Bojanowski et al., 2017)#
Extiende Word2Vec representando cada palabra como la suma de embeddings de sus n-gramas de caracteres:
donde \(\mathcal{G}_w\) es el conjunto de n-gramas de caracteres de \(w\).
Ventaja: maneja palabras OOV y captura morfologia (prefijos, sufijos, raices). Especialmente util para lenguas morfologicamente ricas (espanol, aleman, arabe).
5. Redes Recurrentes#
5.1 RNN (Recurrent Neural Network)#
La RNN procesa la secuencia token por token manteniendo un estado oculto \(\mathbf{h}_t \in \mathbb{R}^d\):
con \(\mathbf{h}_0 = \mathbf{0}\) o aprendible.
Parametros: \(\mathbf{W}_h \in \mathbb{R}^{d \times d}\), \(\mathbf{W}_x \in \mathbb{R}^{d \times n}\), \(\mathbf{W}_y \in \mathbb{R}^{k \times d}\).
5.1.1 Backpropagation Through Time (BPTT)#
El gradiente de la perdida respecto al estado inicial \(\mathbf{h}_0\) requiere multiplicar Jacobianos a lo largo de \(T\) pasos:
Cada factor es:
(para activacion \(\tanh\), donde \(\tanh'(z) = 1 - \tanh^2(z)\).)
Problema del gradiente que desaparece/explota:
Si \(\|\mathbf{W}_h\|_2 < 1\): el producto \(\prod_{k=1}^t \mathbf{W}_h^k \to \mathbf{0}\) exponencialmente. Los gradientes se anulan y la red no puede aprender dependencias largas.
Si \(\|\mathbf{W}_h\|_2 > 1\): el producto diverge exponencialmente. Se mitiga con gradient clipping: si \(\|\mathbf{g}\| > \tau\), escalar \(\mathbf{g} \leftarrow \tau \mathbf{g}/\|\mathbf{g}\|\).
5.2 LSTM (Long Short-Term Memory)#
Hochreiter & Schmidhuber (1997) diseñaron la LSTM para resolver el problema de gradientes mediante una celda de memoria \(\mathbf{c}_t\) con flujo de gradiente no obstruido.
Cuatro compuertas (gates) aprenden que informacion retener, olvidar y emitir:
Actualizacion de la celda (mecanismo clave):
Estado oculto:
donde \(\odot\) es el producto element-wise (Hadamard) y \(\sigma\) es la sigmoide.
Por que funciona: la celda \(\mathbf{c}_t\) se actualiza de forma aditiva. El gradiente fluye sin atenuacion por la ruta \(\mathbf{c}_{t-1} \to \mathbf{c}_t\):
Si \(\mathbf{f}_t \approx \mathbf{1}\) (forget gate abierta), el gradiente se propaga sin cambios, permitiendo capturar dependencias de larga distancia.
Total de parametros: \(4 \cdot (d^2 + d \cdot n + d)\) para un estado oculto de dimension \(d\) y entrada de dimension \(n\).
5.3 GRU (Gated Recurrent Unit)#
Cho et al. (2014) propusieron la GRU como simplificacion de la LSTM con dos compuertas:
La GRU fusiona celda y estado oculto. Menos parametros que LSTM (\(3 \cdot (d^2 + d \cdot n + d)\)), rendimiento comparable en la mayoria de tareas.
5.4 Arquitectura encoder-decoder con RNN#
Para traduccion automatica (seq2seq, Sutskever et al., 2014):
Encoder: comprime la secuencia fuente en un vector de contexto \(\mathbf{c}\):
Decoder: genera la secuencia destino condicionada en \(\mathbf{c}\):
Cuello de botella: comprimir toda la secuencia fuente en un solo vector \(\mathbf{c}\) causa perdida de informacion para secuencias largas. Lo resuelve el mecanismo de atencion.
6. Mecanismo de Atencion#
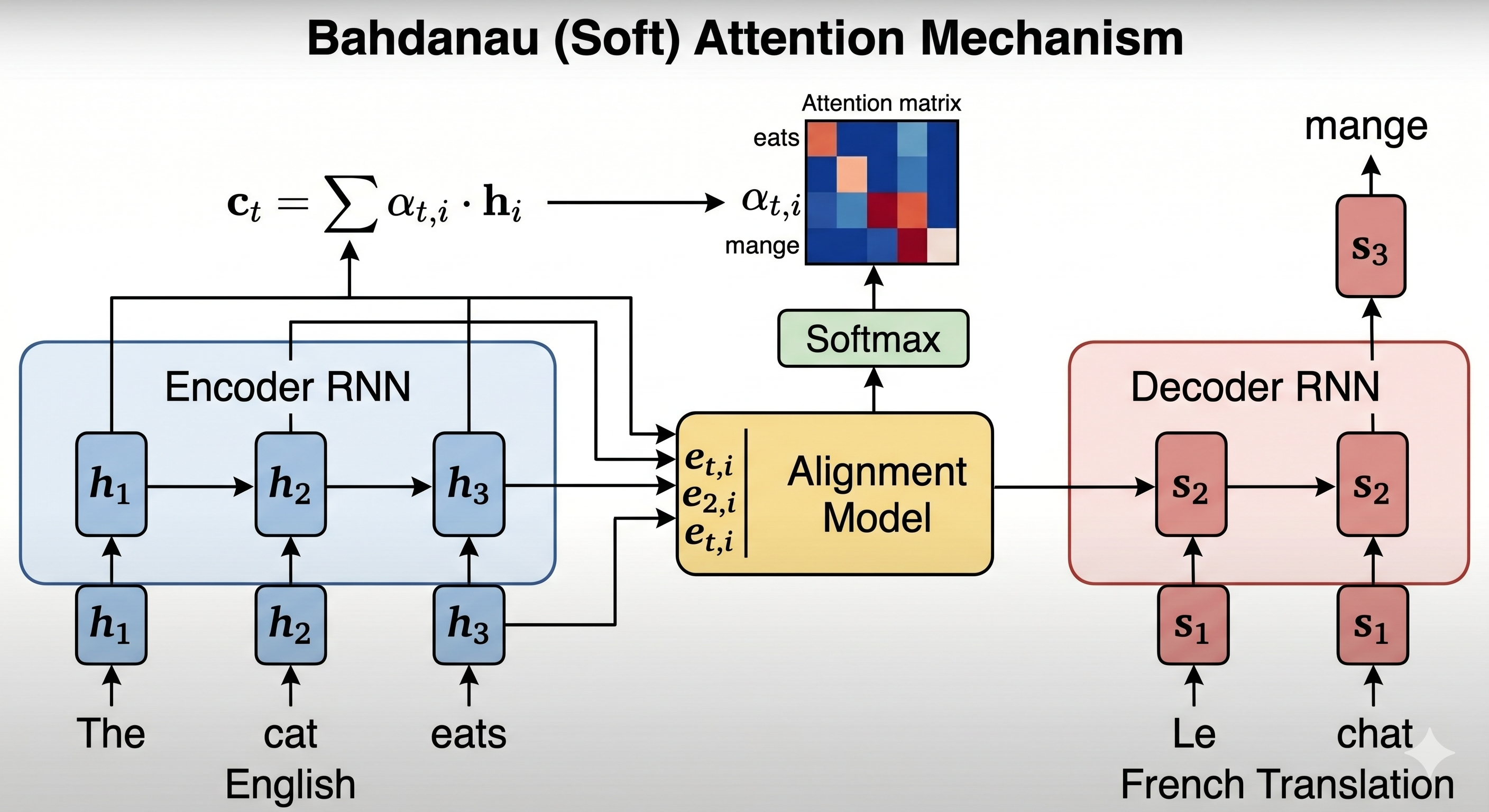
6.1 Atencion de Bahdanau (Bahdanau et al., 2015)#
El decoder no depende de un unico \(\mathbf{c}\) fijo sino que computa un contexto dinamico \(\mathbf{c}_t\) en cada paso:
Score de alineamiento (red feedforward):
Pesos de atencion (distribucion sobre posiciones fuente):
Vector de contexto como suma ponderada:
La actualizacion del decoder incorpora el contexto:
Los pesos \(\alpha_{t,s}\) forman una matriz de alineamiento interpretable que muestra que palabras fuente atiende el decoder al generar cada token destino.
6.2 Atencion de Luong (Luong et al., 2015)#
Tres variantes de la funcion de score:
La variante dot es \(O(1)\) en parametros pero requiere que encoder y decoder tengan la misma dimension.
6.3 Complejidad computacional de la atencion#
Para una secuencia de longitud \(T\) y dimension \(d\):
Operacion |
Complejidad temporal |
Complejidad espacial |
|---|---|---|
Calculo de scores \(T \times T\) |
\(O(T^2 \cdot d)\) |
\(O(T^2)\) |
Softmax |
\(O(T^2)\) |
\(O(T^2)\) |
Suma ponderada |
\(O(T^2 \cdot d)\) |
\(O(T \cdot d)\) |
La atencion es cuadratica en la longitud de secuencia \(T\). Esto motiva variantes eficientes para secuencias largas (Longformer, BigBird, Flash Attention).
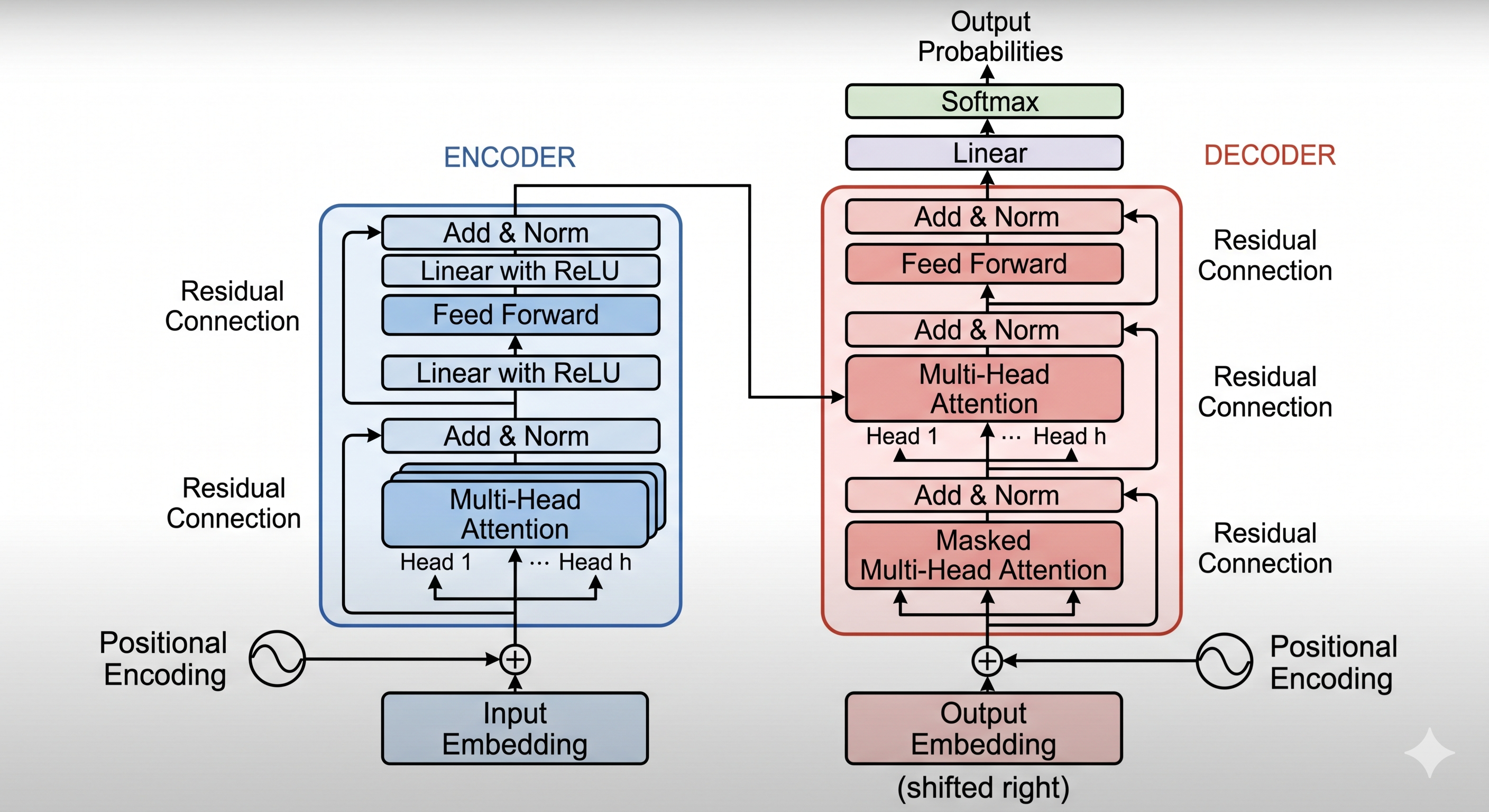
 ## 7. Arquitectura Transformer
## 7. Arquitectura Transformer
Vaswani et al. (2017) eliminaron las recurrencias por completo, basando el procesamiento exclusivamente en atencion.
7.1 Atencion Multi-Cabeza (Multi-Head Attention)#
7.1.1 Atencion Scaled Dot-Product#
Dadas matrices de Query \(\mathbf{Q} \in \mathbb{R}^{T_q \times d_k}\), Key \(\mathbf{K} \in \mathbb{R}^{T_k \times d_k}\) y Value \(\mathbf{V} \in \mathbb{R}^{T_k \times d_v}\):
Por que dividir por \(\sqrt{d_k}\):
El producto interno \(\mathbf{q}^\top \mathbf{k}\) tiene varianza \(d_k\) (si los componentes son i.i.d. con media 0 y varianza 1):
Sin escalar, para \(d_k\) grande los scores son grandes en magnitud, la softmax se satura en regiones de gradiente casi cero. Dividir por \(\sqrt{d_k}\) normaliza la varianza a 1.
Mascara (Causal Masking): en el decoder autoregresivo se aplica una mascara causal para evitar que la posicion \(t\) atienda posiciones \(s > t\):
7.1.2 Multi-Head Attention#
En lugar de una sola atencion en dimension \(d_{model}\), se proyectan las entradas en \(h\) subespacios de dimension \(d_k = d_v = d_{model}/h\):
donde \(\mathbf{W}_i^Q \in \mathbb{R}^{d_{model} \times d_k}\), \(\mathbf{W}_i^K \in \mathbb{R}^{d_{model} \times d_k}\), \(\mathbf{W}_i^V \in \mathbb{R}^{d_{model} \times d_v}\), \(\mathbf{W}^O \in \mathbb{R}^{hd_v \times d_{model}}\).
Intuicion: cada cabeza puede atender a diferentes tipos de relaciones (sintacticas, semanticas, posicionales) de forma simultanea e independiente. La concatenacion y la proyeccion final integran la informacion de todas las cabezas.
Parametros de la capa MHA: \(4 \cdot d_{model}^2\) (tres proyecciones de entrada + proyeccion de salida, cada una de \(d_{model} \times d_{model}\)).
7.2 Red Feed-Forward Posicional (FFN)#
Despues de cada capa de atencion se aplica una red FFN identica e independientemente a cada posicion:
con \(\mathbf{W}_1 \in \mathbb{R}^{d_{model} \times d_{ff}}\), \(\mathbf{W}_2 \in \mathbb{R}^{d_{ff} \times d_{model}}\) y tipicamente \(d_{ff} = 4 \cdot d_{model}\).
Tambien se usan variantes con GeLU (Gaussian Error Linear Unit):
donde \(\Phi\) es la CDF de la normal estandar. GeLU es diferenciable en todo punto, a diferencia de ReLU.
Parametros de la FFN: \(2 \cdot d_{model} \cdot d_{ff}\).
7.3 Codificacion Posicional (Positional Encoding)#
La atencion es invariante a la permutacion de posiciones: \(\text{Attention}(\mathbf{Q}, \mathbf{K}, \mathbf{V})\) no cambia si se permutan filas de \(\mathbf{K}\) y \(\mathbf{V}\) (y correspondientemente de \(\mathbf{Q}\)). Para que el modelo «sepa» la posicion de cada token, se suma un encoding posicional a cada embedding.
Encoding sinusoidal (Vaswani et al., 2017):
para \(pos \in \{0, 1, \ldots, T-1\}\) e \(i \in \{0, 1, \ldots, d_{model}/2 - 1\}\).
Propiedades:
Cada posicion tiene un vector unico de dimension \(d_{model}\).
Para cualquier offset fijo \(k\), \(\text{PE}_{pos+k}\) es una transformacion lineal de \(\text{PE}_{pos}\).
Las funciones sinusoidales permiten extrapolacion a longitudes de secuencia mayores que las vistas en entrenamiento.
Encoding posicional aprendible: en BERT y GPT se aprenden embeddings posicionales como parametros del modelo. Mas flexible pero no extrapola a longitudes no vistas.
RoPE (Rotary Positional Encoding, Su et al., 2021): codifica la posicion relativa rotando los vectores Q y K en el espacio complejo. Usado en LLaMA, Mistral, etc.
donde \(\mathbf{R}_{\Theta,m}^d\) es una matriz de rotacion que depende de la posicion \(m\) y el angulo \(\Theta\).
7.4 Normalizacion de capa (Layer Normalization)#
Batch Normalization (BN) normaliza sobre el batch, problematico para secuencias de longitud variable. Layer Normalization (Ba et al., 2016) normaliza sobre las caracteristicas de un ejemplo individual:
donde:
\(\boldsymbol{\gamma}, \boldsymbol{\beta} \in \mathbb{R}^d\) son parametros aprendibles (escala y desplazamiento). \(\epsilon \approx 10^{-5}\) evita division por cero.
7.5 Conexiones residuales#
Cada sub-capa (MHA y FFN) usa una conexion residual seguida de LayerNorm:
Post-LN (Transformer original):
Pre-LN (usado en GPT-2, T5, LLaMA):
Pre-LN da gradientes mas estables durante el entrenamiento y permite entrenar sin warmup. Las conexiones residuales permiten el flujo directo del gradiente desde la salida hasta las primeras capas:
El primer termino permite que el gradiente llegue sin atenuacion.
7.6 Bloque Transformer completo#
Un bloque Transformer (encoder) aplica en orden:
(notacion Pre-LN: LayerNorm va antes, dentro del residuo.)
El encoder Transformer apila \(L\) de estos bloques. El decoder tiene adicionalmente una capa de cross-attention donde Q proviene del decoder y K, V del encoder:
7.7 Parametros totales del Transformer#
Para un Transformer con \(L\) capas, modelo de dimension \(d_{model}\), \(h\) cabezas, FFN de dimension \(d_{ff}\) y vocabulario \(|\mathcal{V}|\):
Componente |
Parametros |
|---|---|
Embedding tabla |
$ |
MHA por capa |
\(4 d_{model}^2\) |
FFN por capa |
\(2 d_{model} d_{ff}\) |
LayerNorm por capa (x2) |
\(4 d_{model}\) |
Total (sin embedding) |
\(L(4d_{model}^2 + 2d_{model}d_{ff} + 4d_{model})\) |
Para GPT-3 (\(L=96\), \(d_{model}=12288\), \(d_{ff}=49152\), \(|\mathcal{V}|=50257\)): 175 mil millones de parametros.
7.8 Complejidad computacional del Transformer#
Operacion |
Complejidad por capa |
|---|---|
Self-Attention |
\(O(T^2 d)\) tiempo, \(O(T^2)\) memoria |
FFN |
\(O(T d^2)\) tiempo, \(O(Td)\) memoria |
Total por capa |
\(O(T^2 d + T d^2)\) |
Para \(T \ll d\) (secuencias cortas, modelos grandes): domina la FFN \(O(Td^2)\). Para \(T \gg d\) (secuencias largas, modelos pequeños): domina la atencion \(O(T^2d)\).
8. Modelos Preentrenados#
8.1 Paradigma preentrenamiento - ajuste fino#
En lugar de entrenar desde cero en cada tarea, se sigue el paradigma de dos fases:
Preentrenamiento: entrenar un modelo grande en grandes corpus de texto sin etiquetas con un objetivo autosupervisado. \(\theta^* \leftarrow \arg\max_\theta \mathcal{L}_{\text{pre}}(\theta; \mathcal{D}_{pre})\).
Ajuste fino (Fine-tuning): inicializar desde \(\theta^*\) y continuar entrenando en el dataset de la tarea especifica con una cabeza de tarea adicional. \(\hat{\theta} \leftarrow \arg\max_{\theta, \phi} \mathcal{L}_{\text{task}}(\theta, \phi; \mathcal{D}_{task})\).
Ventaja: los parametros del preentrenamiento codifican conocimiento linguistico y del mundo que se transfiere a tareas con pocos datos etiquetados.
8.2 BERT (Devlin et al., 2018)#
Arquitectura: Transformer encoder bidireccional. Lee el contexto completo en ambas direcciones.
Objetivo 1: Masked Language Model (MLM)
En cada secuencia de entrenamiento se enmascara el 15% de los tokens:
80% se reemplaza por
[MASK]10% se reemplaza por un token aleatorio
10% se mantiene igual (pero se predice)
donde \(\mathcal{M}\) es el conjunto de posiciones enmascaradas y \(x_{\backslash \mathcal{M}}\) es la secuencia con las mascaras.
La prediccion de cada token enmascarado utiliza su representacion contextual completa (bidireccional):
Objetivo 2: Next Sentence Prediction (NSP)
Dado un par de oraciones \((A, B)\), predecir si \(B\) es la continuacion real de \(A\). (Criticamente cuestionado en RoBERTa, que lo elimino.)
Token especial [CLS]: el primer token es siempre [CLS]. Su representacion en la ultima capa \(\mathbf{h}_{[CLS]}^L\) se usa como representacion de toda la secuencia para tareas de clasificacion.
Separadores: [SEP] separa oraciones. El formato de entrada es:
[CLS] Oracion A [SEP] Oracion B [SEP]
Embeddings de BERT: suma de tres tipos:
\(\mathbf{E}_{token}\): embedding del token.
\(\mathbf{E}_{segment}\): indica si el token pertenece a la oracion A o B.
\(\mathbf{E}_{position}\): posicion (aprendible, no sinusoidal).
Variantes:
BERT-base: \(L=12\), \(d=768\), \(h=12\), 110M params.
BERT-large: \(L=24\), \(d=1024\), \(h=16\), 340M params.
RoBERTa: BERT reentrenado mas tiempo, sin NSP, con BPE y batches mas grandes.
ALBERT: embeddings factorizados, capas compartidas. Reduce parametros drasticamente.
 ### 8.3 GPT (Generative Pre-trained Transformer)
### 8.3 GPT (Generative Pre-trained Transformer)
Arquitectura: Transformer decoder solo (sin cross-attention). Lee el contexto en una sola direccion (izquierda a derecha) gracias a la mascara causal.
Objetivo: Language Modeling (LM)
Es el objetivo autoregressivo estandar: predecir el siguiente token dado el contexto anterior.
GPT-2: escala el modelo (~1.5B params) y demuestra capacidades emergentes de zero-shot sin ajuste fino.
GPT-3 (Brown et al., 2020): 175B params. Introduce el concepto de in-context learning: el modelo puede adaptarse a una tarea nueva viendo solo unos pocos ejemplos en el prompt, sin actualizar pesos:
donde \(C\) es el conjunto de demostraciones en el contexto.
8.4 Instruccion-tuning y RLHF#
Para modelos conversacionales (ChatGPT, InstructGPT), el preentrenamiento se complementa con:
8.4.1 Supervised Fine-Tuning (SFT)#
Ajuste fino sobre pares (instruccion, respuesta) escritos por humanos:
8.4.2 Reinforcement Learning from Human Feedback (RLHF)#
Paso 1: Entrenar un modelo de recompensa \(r_\phi(x, y)\) que predice la preferencia humana a partir de comparaciones entre respuestas:
donde \(y_w\) es la respuesta preferida y \(y_l\) la no preferida (Bradley-Terry model).
Paso 2: Optimizar la politica del LLM con PPO (Proximal Policy Optimization) maximizando la recompensa con un termino de regularizacion KL:
donde \(\pi_{ref}\) es la politica del modelo SFT (punto de referencia). El termino KL evita que la politica se aleje demasiado del modelo base.
8.4.3 DPO (Direct Preference Optimization)#
Rafailov et al. (2023) mostraron que RLHF con el termino KL tiene solucion analitica. Se puede optimizar la preferencia directamente sin un modelo de recompensa separado:
8.5 Parameter-Efficient Fine-Tuning (PEFT)#
Para modelos grandes (>1B params), el ajuste fino completo es costoso. Las tecnicas PEFT actualizan solo un subconjunto pequeño de parametros.
8.5.1 LoRA (Low-Rank Adaptation, Hu et al., 2021)#
Las actualizaciones de pesos durante el ajuste fino tienen rango intrisecamente bajo. LoRA descompone la actualizacion \(\Delta \mathbf{W}\) como producto de dos matrices de bajo rango:
donde \(\mathbf{W}_0 \in \mathbb{R}^{d \times k}\) se congela, \(\mathbf{B} \in \mathbb{R}^{d \times r}\) y \(\mathbf{A} \in \mathbb{R}^{r \times k}\) con \(r \ll \min(d,k)\) son los unicos parametros entrenables.
La inicializacion es \(\mathbf{B} = \mathbf{0}\), \(\mathbf{A} \sim \mathcal{N}(0, \sigma^2)\) para que \(\Delta \mathbf{W} = \mathbf{0}\) al inicio.
Reduccion de parametros: para \(d = k = 4096\) y \(r = 8\): \(4096^2 \approx 16.7M\) vs \(2 \times 4096 \times 8 = 65536 \approx 65K\) (reduccion de 256x).
9. Tareas de NLP#
9.1 Clasificacion de texto#
Entrada: secuencia \(\mathbf{x}\). Salida: etiqueta \(y \in \{1, \ldots, C\}\).
Con BERT: tomar \(\mathbf{h}_{[CLS]}^L\) y aplicar una capa de clasificacion:
Entrenada con Cross-Entropy (negative log-likelihood):
9.2 Reconocimiento de entidades nombradas (NER)#
Tarea de etiquetado de secuencias. Para cada token se predice su etiqueta:
Esquema de etiquetado BIO: B-PER, I-PER, O para separar entidades adyacentes.
CRF (Conditional Random Field) sobre las salidas del Transformer captura dependencias entre etiquetas consecutivas:
donde \(\phi\) son los scores unarios y \(\psi\) los scores de transicion.
9.3 Question Answering extractivo#
Dado un contexto \(C\) y una pregunta \(Q\), predecir el span \([s, e]\) del contexto que contiene la respuesta.
Con BERT se predicen dos distribuciones sobre posiciones:
La respuesta es el span \([s, e]\) que maximiza \(p_s^{start} \cdot p_e^{end}\) sujeto a \(s \leq e\).
Perdida: suma de las cross-entropies para inicio y fin:
9.4 Traduccion automatica#
Modelo seq2seq con Transformer encoder-decoder.
En entrenamiento se usa teacher forcing: el decoder recibe los tokens objetivo reales como entrada, no sus propias predicciones anteriores.
En inferencia se usa beam search con amplitud \(B\):
En cada paso se mantienen las \(B\) hipotesis parciales con mayor log-probabilidad acumulada:
donde el exponente \(\alpha \in [0.6, 0.7]\) es el length penalty que evita favorecer sistematicamente secuencias cortas.
9.5 Generacion de texto#
Para modelos autorregresivos (GPT), la generacion se controla con varias estrategias de decodificacion:
Temperatura: escala los logits antes del softmax, controlando la concentracion de la distribucion:
\(\tau \to 0\): argmax (greedy, determinista).
\(\tau = 1\): distribucion original del modelo.
\(\tau > 1\): distribucion mas uniforme (mas diversidad, mas errores).
Top-k sampling: muestrear solo de los \(k\) tokens mas probables:
Nucleus sampling (top-p): muestrear del nucleo de tokens cuya probabilidad acumulada supera un umbral \(p\):
Adaptativo: para distribuciones concentradas el nucleo es pequeño; para distribuciones planas es grande.
10. Metricas de Evaluacion#
10.1 BLEU (Bilingual Evaluation Understudy)#
BLEU (Papineni et al., 2002) mide la precision de n-gramas de la hipotesis respecto a las referencias.
Precision de n-gramas modificada:
El termino «clip» \(\min(\cdot, \max(\cdot))\) evita que repetir tokens inflados la precision.
Brevity Penalty penaliza hipotesis mas cortas que la referencia:
donde \(c\) es la longitud de la hipotesis y \(r\) la longitud de referencia efectiva.
BLEU final:
con \(N = 4\) y \(w_n = 1/N\) tipicamente (media geometrica de las precisiones 1 a 4-grama).
Limitaciones: no captura semantica, penaliza sinonimos, sensible a segmentacion. Se complementa con METEOR, ROUGE y BERTScore.
10.2 ROUGE#
ROUGE (Lin, 2004) se usa principalmente para evaluacion de resumenes, midiendo recall de n-gramas:
ROUGE-L usa la longest common subsequence (LCS):
10.3 BERTScore#
BERTScore (Zhang et al., 2019) usa embeddings de BERT para medir similitud semantica a nivel de token:
donde \(\mathbf{x}_i\) son los embeddings contextuales normalizados del token \(i\). Captura similitud semantica que BLEU ignora.
10.4 Perplejidad (revision)#
Para un modelo de lenguaje neuronal sobre un corpus de evaluacion con \(N\) tokens:
Es la metrica intrinseca estandar para comparar modelos de lenguaje independientemente de la tarea.
 ---
---
11. Referencias#
Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. JMLR, 3, 1137–1155.
Mikolov, T., et al. (2013). Distributed representations of words and phrases and their compositionality. NeurIPS 2013.
Pennington, J., Socher, R., & Manning, C. (2014). GloVe: Global vectors for word representation. EMNLP 2014.
Bahdanau, D., Cho, K., & Bengio, Y. (2015). Neural machine translation by jointly learning to align and translate. ICLR 2015.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Cho, K., et al. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. EMNLP 2014.
Vaswani, A., et al. (2017). Attention is all you need. NeurIPS 2017.
Devlin, J., et al. (2018). BERT: Pre-training of deep bidirectional transformers for language understanding. NAACL 2019.
Brown, T., et al. (2020). Language models are few-shot learners. NeurIPS 2020.
Rafailov, R., et al. (2023). Direct preference optimization. NeurIPS 2023.
Hu, E., et al. (2021). LoRA: Low-rank adaptation of large language models. ICLR 2022.
Su, J., et al. (2021). RoFormer: Enhanced transformer with rotary position embedding. arXiv:2104.09864.
Zhang, T., et al. (2019). BERTScore: Evaluating text generation with BERT. ICLR 2020.
Papineni, K., et al. (2002). BLEU: A method for automatic evaluation of machine translation. ACL 2002.
Sennrich, R., Haddow, B., & Birch, A. (2016). Neural machine translation of rare words with subword units. ACL 2016.